Python 爬虫入门与进阶
本文档整理了 Python 爬虫开发中涉及的核心库和关键技术,包括网页下载、数据解析、动态网页处理等。
1. 网页下载库 requests
requests 是 Python 中最流行、最易用的 HTTP 请求库,用于从服务器下载网页内容。
发送请求
requests.get/post()
该方法接受多个参数以定制请求:
url: 目标网页的 URL。params: (字典) URL 查询参数,如{'id': 123}会被附加为?id=123。data: (字典或字符串) 用于 POST 请求的表单数据。json: (字典) 用于 POST/PUT 请求的 JSON 数据,requests会自动序列化并设置Content-Type。headers: (字典) 自定义请求头,如User-Agent、Cookie等。cookies: (字典) 附加到请求中的 Cookie。timeout: (秒) 请求超时时间。allow_redirects: (布尔值) 是否允许自动处理重定向,默认为True。verify: (布尔值或证书路径) 是否验证 HTTPS 证书,默认为True。
处理响应对象 response
请求成功后返回一个 response 对象,包含服务器的响应信息:
r.status_code: HTTP 状态码,200表示成功。r.text: 响应内容的字符串形式。r.content: 响应内容的字节串形式,适用于下载图片、视频等二进制文件。r.encoding:requests推测的编码格式,可能不准确。r.headers: 响应头字典。r.cookies: 服务器设置的 Cookie 对象。r.url: 请求的最终 URL(处理重定向后)。
注意:处理乱码
如果 r.text 出现乱码,通常是因为 requests 自动检测编码失败。可以检查响应头 Content-Type 或 HTML meta 标签中的 charset,然后手动设置编码:
r.encoding = 'utf-8' # 或者 'gbk' 等2. 网页解析
获取到网页的 HTML 源码后,下一步就是从中提取有价值的信息。
静态网页解析:Beautiful Soup
Beautiful Soup 是一个强大的 Python 库,用于从 HTML 或 XML 文件中提取数据。它能将复杂的 HTML 文档转换成一个易于操作的 Python 对象树。
核心用法:
xfrom bs4 import BeautifulSoup
# soup = BeautifulSoup(html_doc, 'html.parser') # 使用 Python 内置解析器soup = BeautifulSoup(html_doc, 'lxml') # 推荐使用 lxml,速度更快
# 查找第一个匹配的标签tag = soup.find('a')
# 查找所有匹配的标签tags = soup.find_all('a', class_='sister', limit=2)
# 获取标签内容和属性print(tag.name) # 'a'print(tag['href']) # 'http://example.com/elsie'print(tag.string) # 'Elsie'find() 和 find_all() 的高级用法
按标签名和 CSS 类名查找:
xxxxxxxxxx# 查找所有 class 为 "story" 的 <div> 标签soup.find_all('div', class_='story')使用正则表达式进行模糊匹配:
xxxxxxxxxximport re# 查找所有 href 属性包含 "lacie" 的 <a> 标签soup.find_all('a', href=re.compile(r"lacie"))按属性值查找:
xxxxxxxxxx# 查找所有 data-foo="bar" 的标签soup.find_all(attrs={"data-foo": "bar"})
动态网页解析:Selenium
现代网站大量使用 JavaScript (AJAX) 动态加载内容。requests 只能获取初始的 HTML,无法执行 JS。Selenium 是一个浏览器自动化测试工具,它可以驱动一个真实的浏览器(如 Chrome, Firefox)加载网页,执行 JS,并获取最终渲染后的页面内容。
Selenium 基础
xxxxxxxxxxfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.options import Options
# --- 配置无头模式 (不打开浏览器窗口) ---chrome_options = Options()chrome_options.add_argument("--headless")driver = webdriver.Chrome(options=chrome_options)
# 打开网页driver.get("https://example.com")
# 定位元素element = driver.find_element(By.ID, 'some_id')
# 获取元素信息print(element.text)print(element.get_attribute('href'))
# 关闭浏览器driver.quit()注意: Selenium 4.x 版本后,find_element_by_* 系列方法已弃用,推荐使用 find_element(By.XXX, 'value')。
Selenium 元素定位策略
Selenium 提供了多种定位元素的方式,其中 XPath 和 CSS Selector 功能最为强大。
| 定位方式 | By 枚举 | 描述 |
|---|---|---|
| ID | By.ID | 按 id 属性定位,速度最快 |
| Class Name | By.CLASS_NAME | 按 class 属性定位 |
| Name | By.NAME | 按 name 属性定位 (常用于表单元素) |
| Tag Name | By.TAG_NAME | 按 HTML 标签名定位 (div, a 等) |
| Link Text | By.LINK_TEXT | 按链接的完整文本内容定位 (<a> 标签) |
| Partial Link Text | By.PARTIAL_LINK_TEXT | 按链接的部分文本内容定位 (<a> 标签) |
| CSS Selector | By.CSS_SELECTOR | 使用 CSS 选择器语法定位,功能强大 |
| XPath | By.XPATH | 使用 XPath 表达式定位,功能最强大 |
XPath 常用表达式
| 表达式 | 描述 |
|---|---|
//div | 选取所有 <div> 元素 |
/html/body/div[1] | 从根节点绝对路径定位第一个 div |
//div[@id='main'] | 选取 id 属性为 main 的 div |
//a/text() | 获取 <a> 标签的文本内容 |
//a/@href | 获取 <a> 标签的 href 属性值 |
//*[contains(@class, 'item')] | 选取 class 属性包含 item 的所有元素 |
//*[starts-with(@id, 'prefix')] | 选取 id 属性以 prefix 开头的所有元素 |
//div/following-sibling::p | 选取 div 后面的所有同级 p 元素 |
Selenium 与 Beautiful Soup 结合使用
Selenium 擅长模拟浏览器行为和处理动态内容,而 Beautiful Soup 在解析复杂 HTML 结构时语法更简洁、更灵活。我们可以结合两者的优点:
xxxxxxxxxxfrom selenium import webdriverfrom bs4 import BeautifulSoup
driver = webdriver.Chrome()driver.get("https://some-dynamic-website.com")
# ... (执行滚动、点击等操作,等待页面加载完成) ...
# 1. 获取 Selenium 渲染后的页面源码html_source = driver.page_source
# 2. 将源码交给 Beautiful Soup 解析soup = BeautifulSoup(html_source, 'lxml')
# 3. 使用 Beautiful Soup 的强大功能提取数据titles = soup.find_all('h2', class_='post-title')for title in titles: print(title.text)
driver.quit()3. Selenium 进阶操作
鼠标与键盘操作
ActionChains 类用于模拟复杂的鼠标和键盘操作。
xxxxxxxxxxfrom selenium.webdriver.common.action_chains import ActionChainsfrom selenium.webdriver.common.keys import Keys
# 创建 ActionChains 对象actions = ActionChains(driver)
# 鼠标悬停element_to_hover_over = driver.find_element(By.ID, 'menu')actions.move_to_element(element_to_hover_over).perform()
# 右键点击actions.context_click(element_to_hover_over).perform()
# 键盘操作 (输入并按回车)search_box = driver.find_element(By.NAME, 'q')search_box.send_keys("Selenium" + Keys.RETURN)窗口切换
当点击链接打开新标签页时,需要手动切换 WebDriver 的控制焦点。
xxxxxxxxxx# 获取所有窗口的句柄all_windows = driver.window_handles
# 切换到最新打开的窗口 (通常是最后一个)driver.switch_to.window(all_windows[-1])
# ... 在新窗口中操作 ...
# 切换回原始窗口driver.switch_to.window(all_windows[0])Cookie 操作
自动化登录后,可以获取 Cookie 用于后续 requests 请求,实现免登录访问。
xxxxxxxxxx# 模拟登录...# ...
# 获取登录后的所有 cookiescookies = driver.get_cookies()
# 将 cookies 转换为 requests 可用的格式requests_cookies = {cookie['name']: cookie['value'] for cookie in cookies}
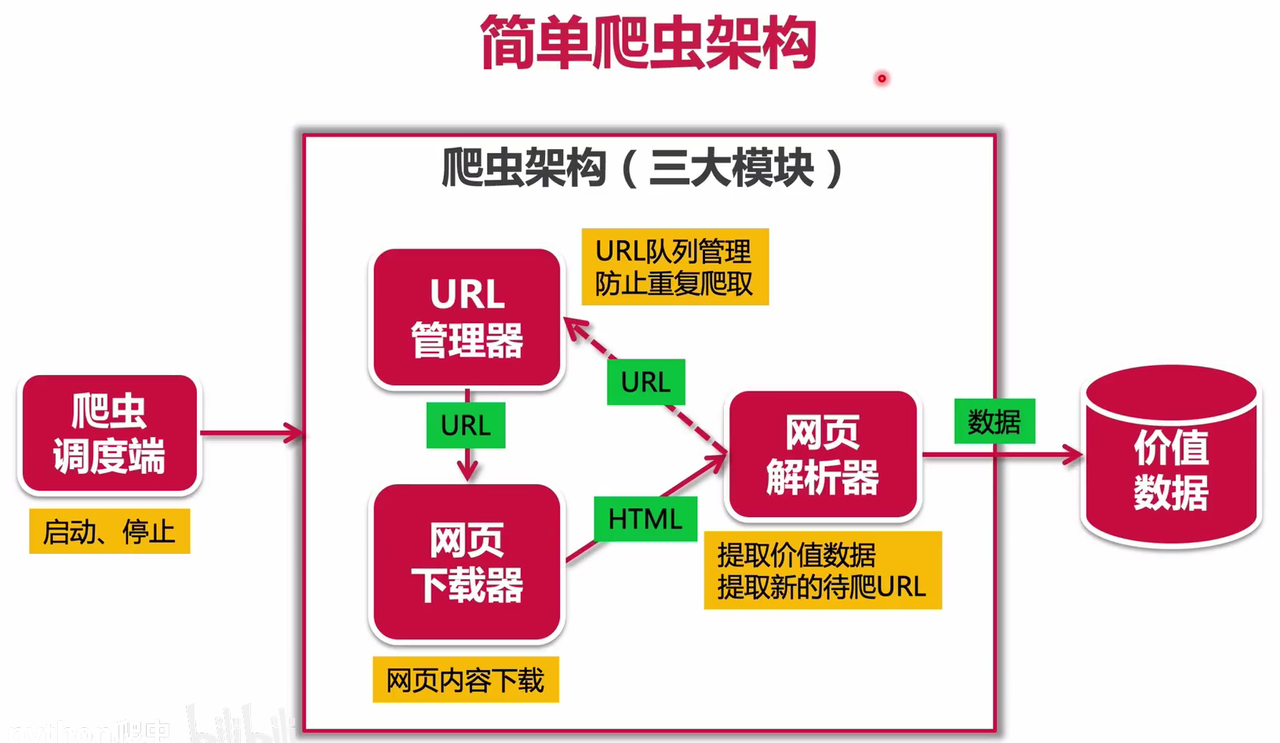
# 使用 requests 携带 cookie 发送请求session = requests.Session()response = session.get("https://example.com/profile", cookies=requests_cookies)4. 爬虫架构与实战技巧
URL 管理器
在爬取整个网站时,需要一个 URL 管理器来:
存储待爬取的 URL 集合。
存储已爬取的 URL 集合,避免重复爬取。
xxxxxxxxxxclass UrlManager: def __init__(self): self.new_urls = set() self.old_urls = set()
def add_new_url(self, url): if url and url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) # ... 其他方法 ...反爬策略与应对
User-Agent 伪装: 在
headers中设置User-Agent,模拟主流浏览器。IP 代理: 使用代理 IP 池,避免单一 IP 请求过于频繁被封禁。
Cookie 处理: 登录获取 Cookie,或直接在请求中携带已知的 Cookie。
处理验证码: 使用 OCR 技术识别简单验证码,或接入第三方打码平台。
延时与随机化: 在请求之间加入随机延时,模拟人类行为。
分析 AJAX 请求: 打开浏览器开发者工具 (F12),在
Network面板中分析页面动态加载数据的 API 接口,直接请求这些接口通常比模拟浏览器更高效。
soup = BeautifulSoup(html_doc, "html.parser")
回复删除